2024. 6. 25. 16:10ㆍRL
https://arxiv.org/pdf/2107.00591
Keywords: Deep Reinforcement Learning, Offline RL, Fine-tuning
요약
Offline learning 이후 Online learning 을 무작정 진행하게 되면, offline learning으로 얻은 pretrained policy가 초기화 될 수 있음.
이는
1. offline dataset과 online dataset의 distribution shift로 인한 Out-of-Distribution.
2. unseen action에 대한 Q function의 overestimation으로 인한 Out-of-Distribution.
방법론은... 그저 그럼, 그냥 해당 논문을 통해 offline RL to online RL에서 Out-of-distribution이 왜 발생하는지 확인할 수 있음.
1. Abstract
1.1. Offline RL
Offline RL 등장 이후, offline dataset을 통해 훌륭한 학습자의 행동을 만들어 낼 수 있음.
하지만, 학습된 학습자의 질적 요소와 사용 목적에 크게 의존된다는 문제가 존재.
해당 단점으로 인해 Online RL과 같이 환경과 상호작용, 즉 Fine-Tune[FT]이 필요로 하게됨.
1.2. Offline with Online
그렇다고 무식하게 offline + online 을 병행할 수 없는 주요 문제가 있음.
1. state-action distribution shift로 인해 FT 동안 Error가 누적
2. 1로 인해 Offline-RL로 이쁘장하게 만들어진 Policy가 붕괴 [즉, init policy의 의미가 없어짐]
1.3. In this paper
이러한 문제점을 해결하기 위해서 본 논문은 Balanced Replay scheme[BRs]을 구성
1.4. How?
1. offline에서는 Multiple Q functions을 학습하여, 최초 학습 단계에서 새로운 state에 대한 부적합한 action overoptimism을 방지
2. 환경과 상호작용하는 online learning 동안 해당 환경에서 얻은 데이터에 대해 우선순위[prioritizes] 샘플하는 동시에, offline dataset과 유사한 policy를 샘플
1.5. Contribution
1. 향상된 sample-efficiency
2. 당연히 final performance in robotic agent tasks
2. Introduction
2.1. Offline learning leads to Suboptimal
1. 학습하기 위해 제공된 데이터들이 suboptimal 일 수 있음
2. 학습 완료된 후 학습자가 사용되는 환경이 데이터를 취득한 환경과 다를 수 있음
2.2. Offline with Online [About FT]
off-policy 기반인 Offline RL은 FT를 진행하기 어려운데, 이는 Abstract에서 언급했듯 distribution shift이 발생, 즉 offline 데이터에서 보지 못한 데이터에 대해 취약.
이는 Online 데이터에 대해 Q-function이 out-of-distribution[OOD]로 인해 부적절한 평가를 내리기 때문.
이러한 결과로 policy update에 부정적인 영향을 끼침과 동시에 offline learning을 통해 취득한 pre-trained policy가 의미 없어짐.
2.3. BRs
데이터 취득은 Abstract에 설명되어 있으며, 이때 우선순위의 기준은 online-ness을 통해 책정, 해당 방법을 통해서 Q-learning이 online 데이터에 취약하지 않도록 유도[유도 했을 뿐 여전히 취약; 2.4.에서 서술]. 연쇄적 효과로 policy update 또한 긍정적 효과
2.4. Multiple-Q function
BRs 만으로는 충분한 결과를 낼 수 없음. 이는 Q-function이 보지 못한 데이터에 대해 너무나도 민감하게 반응하기 때문, 따라서 이를 해결하기 위해 Multiple-Q function을 적용하여 Ensemble 진행
이러한 결과로 최초 Online learning,즉 FT시에 policy가 behavior policy 근처에 있을 수 있도록 함.
2.5. 실험 환경
MuJoCo, locomtion tasks from the D4RL, Vision-based robotic manipulation tasks
3. Background
3.1. Reinforcement Learning [Skip!]
3.2. Soft actor-critic [Skip!]
3.3. Conservative Q-learning [CQL]
해당 방법은 비관적으로[pessimistically] 현재 학습 중인 policy를 평가하는 방법론임.
비관적인 시각으로 바라보게 하는 방법은 당연히 Q-value function을 이용함으로써 달성됨.

빨간색 term: Bellman Backup 을 적용하여, Q value를 업데이트
파란색 term: regularization term으로 offline dataset에 없는 [unseen] action에 대해 Q value가 overestimation 하는 것을 방지
즉, Q value를 update 하면서, unseen action에 대해 정규화 진행
비관적인 Q function이 FT 단계에 이점을 가져다 줌.
4. Fine-tuning Offline RL Agent
해당 부분은 Offline to Online RL 학습시 distribution shift가 발생하는 원인에 대해서 다룸.
즉, Fine-tuning 단계로 인한 distribution shift의 원인.
4.1. Distribution Shift in Offline-to-Online RL
어떤 것에 대한 distirbution shift 인가?
online dataset [state, action] 과 offline dataset [state, action]간의 shift 임.
이게 왜 문제가 되는데?
학습자가 unseen state-action [offline dataset에 존재하지 않은 dataset, 다시말해 오직 online dataset에서만 존재]
을 경험하는 경우, Q function의 결과값[Q value]이 부정확할 수 있음. [너무 당연함]
해당 Q value를 통해 Policy를 학습하게 되면, offline RL를 통해 학습된 좋은 Policy [e.g. Behavioral cloning을 통해 얻은 pretrained policy]가 붕괴됨.
만약, Offline dataset의 distribution이 너무나도 좁은 경우[std 값이 작은 경우], 해당 문제는 더욱 쉽게 발생.
4.2. Sample Selection
야 그러면, offline learning에서 취득한거 사용하면 되잖아
Online learning에서 취득한 samples는 distribution shift로 인해 OOD 에 엄청나게 취약함. [못본 데이터 존재]
반대로 Offline learning에서 취득한 samples는 OOD에 대해 안전하지만, fine-tuning이 느림. [탐험이 어렵]
음.. 그럼 online dataset이랑 offline dataset을 섞으면?
replay buffer에 online sample과 offline sample를 넣게되면, 학습자는 online sample에 대해 충분한 학습을 할 수 없음.
[해당 문제는 offline sample이 무진장 많을 때 문제가 됨]
4.3. Choice of Offline Q-function
앞에서는 distribution shift 문제의 원인 중 online과 offline dataset 차이를 분석.
해당 부분은 Offline Q-function에 대해서 이야기 함.
특히, CQL에서 사용된 비관적으로 학습된 Q-function에 대해서 이야기.
비관적인 Q function vs 그냥 Q function
random policy로 생성된 dataset에 대해서는 둘다 유사한 결과.
하지만, Expert policy가 포함이 되는 순간 이 둘의 차이는 극명하게 달라짐.
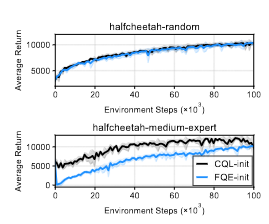
왜 그런거야?
그냥 Q function이 unseen action에 대해서 과도하게 낙관적으로 판단[overestimation]하기 때문.
그로 인해, policy가 안좋은 행동을 선호할 가능성이 높아짐. 이게 누적이 되면, 최종적으로 전체 Trajectory [Episode]가 개판.
그럼 CQL, 그러니까 비관적인 Q function은 왜 좋은데?
이는 처음 접한 unseen action을 통해 생성된 Q value에 대해 비관적으로 접근하고, 이후에 점차 [비관적인]관점을 개선해 나가면서 좋은 학습 결과를 이끌어 냄.
즉, Trajectory가 offline dataset에 엄청나게 벗어나지 않고 합리적인 관점에서 벗어나 최종적으로 전체 Trajectory가 크게 개판나지 않도록 함.
5. Method
당연하게도 앞서 언급한 방법론들 다 적용한 느낌.
5.1. Balanced Experience Replay
앞에서 언급했듯이 dataset으로 인한 문제가 있으니까 Replay buffer를 변형할게~.
원래 문제가 뭐였지? dataset의 distribution shift가 문제였지! 그럼 두 데이터 셋의 차이가 큰것은 OOD에 취약하겠군!.
그렇다고 모든 데이터 셋에 대한 likelihood를 계산하여 density ratio를 추정하는 것이 현실적으로 무리가 있어 보이는데?
걱정말라, Replay buffer에 대한 network를 따로 학습하면 된다. [likelihood-free density ratio]
KLD는 값의 범위가 무한대이니 값의 비교가 쉽지 않다. 따라서 JSD의 하한을 사용한다.
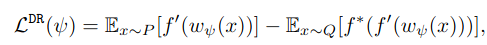
응? Prioritized replay buffer는 언제 사용해?
위에서 dataset 끼리의 distribution 차를 구했으니, 이를 Prioritized Value라고 할께, PER 논문에서 나온 sampling 기법 그대로 적용할거야 ^^. 참고로, 해당 값이 큰 것은 한번 이상은 봤던 data야.
5.2. Pessimistic Q-Ensemble
Distribution shift 현상을 완화하기 위해서, 1개 이상의 Q function을 사용. [성능을 강건화 하겠다!]
이를 위해 N개의 Pretrained CQL 을 다음과 같은 수식을 통해 Ensembling.
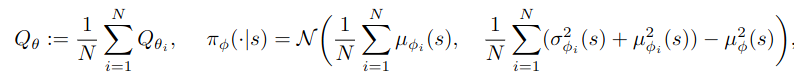
논문을 작성했으니 효과가 있겠지만, 굳이 해석하면, init weight가 다르므로 unseen에 대한 값도 다 다를 것이다.
따라서 이를 Ensembling 함으로써, 강건함을 꾀하겠다.
'RL' 카테고리의 다른 글
| [Exploration Method] Smooth Exploration for Robotic ReinforcementLearning 0 | 2024.11.04 |
|---|