2024. 9. 4. 16:19ㆍRLHF
DPO model이나 Preference Based PPO는 필연적으로 reference model이 필요하다.
1. 이는 reference model의 output을 이용하여 좋고 나쁨을 명확하게 구분이 가능하도록 하기 위함이며
2. model이 reward model에 너무 빨려들어가지 않도록 하기 위함이다.
이번 review는 2번에 대해서 의문을 가진 논문을 알아본다.
기본적으로 2번을 성취하기 위해서는 다음과 같은 수식이 필요하다.
LKLD=β×KLD(πrefer,πθ)
β의 크기에 따라 reference model을 얼마만큼 따를 것이고 반대로 그렇지 않을 것인지 결정하게 된다.
여기까지 이해를 했다면, 본 논문과 동일한 질문을 가지게 될 것이다.
"만약 reference model이 부정확하다면? 그렇다면 β를 어떻게 조절해야 할까?"
or
"preference dataset이 불안정 [preferred vs dispreferred가 불명확] 하다면? 이는 reference model도 부정확한 값을 보여줄 것이고 최종적으로 β를 어떻게 조절해야 할까?"
본 논문 리뷰를 통해서 해당 질문에 대한 답변을 얻기 바란다.
1. 초록
DPO의 성능은 fine-tuning 과정에서 preference data의 질적인 측면 뿐만 아니라 parameter β 에도 민감하다.
본 논문은
1. preference dataset의 질quality과 β의 관계에 따른 DPO의 성능을 보여주며,
2. constant β 의 한계를 해결하기 위해 batch level에 따른 두가지의 dynamic β를 보여준다.
2. Intro
DPO는 초록에서 말했 듯, preference data의 질적인 측면과 parameter β에 민감하다.
특히 β의 경우 reference model πref과 new preferences πθ 의 information 차이를 나타내므로, 값이 클수록 공격적으로 [gradient가 크다] 반대로 값이 작을 수록 수비적으로 업데이트 하게 된다.
그러니까 즉, 최대한 reference model과 유사하게 유도한다.

간단한 실험으로, 만약 preferred sample과 dispreferred sample 간의 차이가 미미한 경우[low gap = high quality], β가 커질 수록 [0.1 -> 0.5]
preferred sample이 이길 확률이 42%에서 33%로 감소된 것을 볼 수 있다.
위 실험과는 반대로, preferred sample과 dispreferred sample 간의 차이가 큰 경우[high gap = low quality], β가 커질 수록 preferred sample이 이길 확률이 증가함을 볼 수 있다. 즉, DPO 의 성능이 좋아지고 있음을 보여준다.
두 실험의 결과로써, preference dataset의 질[quality]에 따라 세밀한 β 조정이 필요함을 보여준다.
본 논문에서는 최종적으로 2가지의 방법을 설명한다.
1. Dynamic β Calibration at Batch-Level
학습의 불안정성을 완화하기 위해, 각 batch 마다 동적으로 β를 계산한다.
해당 방법은 data의 질에 따라 조정되며, high-quality,low-gap의 경우, β는 감소시켜 확실한 업데이트를 유도한다.
반대로 low-quality,high-gap의 경우 β를 증가시켜 신중한 업데이트를 촉진하고 노이즈에 대한 과적합을 방지한다.
2. β-Guided Data Filtering
해당 방법은 data filtering approach 방법으로, 빈번하게 나타나는 이상값[outliers]를 제거한다.
즉, 가장 신뢰할 수 있고 대표적인 샘플에 우선 순위를 지정하여 β 추정의 충실도를 유지한다.
결과적으로 학습을 불안정하게 할 수 있는 이상값[outliers]의 영항을 줄여배치 수준 β 교정의 정밀도와 견고성을 향상시킨다.
instance-level 은 사용하지 않는데, 이는 batch-level과 비교시 불안정한 학습을 보여주기 때문이다.
[아무래도 sample 하나하나를 고려하게 되는 경우 값이 크게 튀기 때문일 것]
3. Related Works
생략...
4. Preliminaries
일부 생략...
Preference based PPO는 다음과 같은 loss function을 가진다.
3 번 수식에서 빨간색이 우리가 집중해서 봐야할 수식이다.
여기서 $\pi_{ref} 는 fixed reference model로 backpropagation 이 되지 않는다.
위 3 수식 전체를 DPO에서 다음과 같이 변경한다.
그럼에도 불구하고 여전히 β가 살아 있음을 확인할 수 있다. 즉, β의 영향이 살아 있다.
5. Method
5.1. Motivation: The Impact of Pairwise Data Quality on β Selection
일부 생략...
5.1.1 Findings: 1 The optimal value of β varies with data quality, reflecting divergent performance patterns across datasets.
위 그림을 보면, 3가지의 data gap에 따른 β parameter의 영향을 볼 수 있다.
low-gap dataset의 경우:
β가 작아질 수록 좋은 성능을 보여준다. 이는, 유익한 내용은 더 낮은 β를 허용하여 보다 실질적인 업데이트를 촉진하고 그에 따라 정렬 정확도를 향상시키기 때문이다.
mixed-gap dataset의 경우:
미묘한 성능 패턴을 보여 다양한 데이터 품질에 적응하기 위한 동적 β 보정 전략의 필요성을 시사한다.
high-gap dataset의 경우:
낮은 β를 사용하면 과적합이 발생하여 정렬 프로세스가 훼손되는 것을 볼 수 있다.
5.1.2. Findings: 2 The dataset exhibits notable outliers.
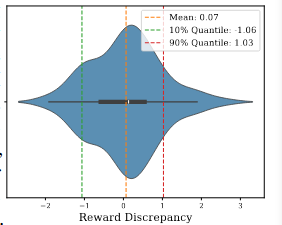
밀도 그래프의 꼬리가 강조된 백분위수 범위를 넘어서 확장되는 것을 보면, 상당히 높은 혹은 낮은 보상 불일치를 가진 data samples가 존재함을 알 수 있다.[outlier 존재]
특히, positive samples에 대해 negative samples보다 현저히 높은 보상을 받는 경우는 정보적 가치가 낮을 가능성이 높다.
이는 이러한 불일치가 모델의 학습 과정에 크게 기여하지 않을 수 있기 때문이며, 반대의 경우는 레이블링 오류가 있을 가능성을 의미한다. 두 경우 모두 합리적인 분포 범위에서 벗어나기 때문에 이상치로 분류한다.
5.2. Method: Dynamic β Calibration in DPO
위와 같은 문제를 해결하기 위한 방법을 정의하기 전에 다음과 같은 질문에 답변을 해야한다.
"우수한 β를 선택하는 기준은 무엇일까?"
논문에선 해당 대답에 대해 2가지의 원칙을 제시한다.
원칙 1. 최적의 β 값은 dataset의 품질에 따라 반응해야한다.
원칙 2. β값 선택은 outlier의 영향을 최소로 해야한다.
5.2.1. Dynamic β Calibration at Batch-Level
instance-level dynamic β adaption 은 다음과 같은 수식을 따른다.
참고로 β_0 DPO에서 주로 사용되는 0.1 값, M_0 는 사전에 정의 된 임의 값, α \in [0,1]는 scaling factor
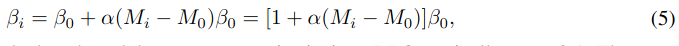
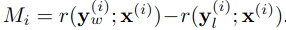
해당 5 수식은 M_i와 \beta_i가 점진적으로 업데이트 되지만, Intro에서도 언급했듯이 학습이 불안정함을 보여줬다.
따라서 minbatch approach를 활용한 사전 연구를 바탕으로 다음과 같이 batch-level dynamic β adaption 을 정의한다.
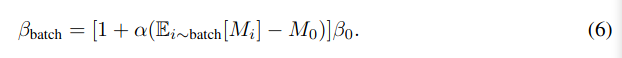
실제 응용에서 임계값 M_0는 moving average updating 방식을 사용하여 global mean M_i를 사용하여 추정할 수 있다.
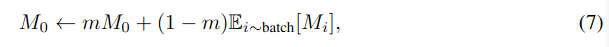
where m ∈ [0, 1) is a momentum coefficient
5.2.2. β-Guided Data Filtering
β 선택 과정속에서 이상치의 영향을 줄이기 위해 β-guided data filtering mechanism을 소개한다.
68-95-99.7규칙 에 따라서, 각각의 M_i 를 정의하면 다음과 같다.
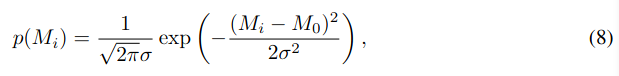
where M_0 and σ represent the mean and standard deviation of M_i across the training dataset.
여기서도 σ를 구할때, moving average 방법을 적용한다.
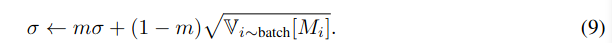
이 확률적 가중치 방법은 각 sample의 상대적 중요성을 구분하여, 계산된 확률 p(M_i)를 기반으로 |batch| × ρ 샘플중복 없이을 선택하는 과정을 안내한다. 여기서 ρ는 선택 비율을 나타내며, 기본값은 0.8로 설정된다.
이 값은 훈련 효율성과 모델 정확도를 최적화하기 위한 초기 실험을 통해 검증되었다. 이 과정은 각 훈련 배치에 대해 반복되며, train data가 지속적으로 업데이트되어 가장 유용한 sample을 반영한다.
β로 유도된 해당 방법의 도입은 모델이 이상치[outlier]에 강해지도록 도와주며, 이를 통해 β 값을 정확하게 추정하는 데 중요한 역할을 한다.
6. Experiments
6.1. Empirical Evaluation of β-DPO on Dialogue Generation and Summarization
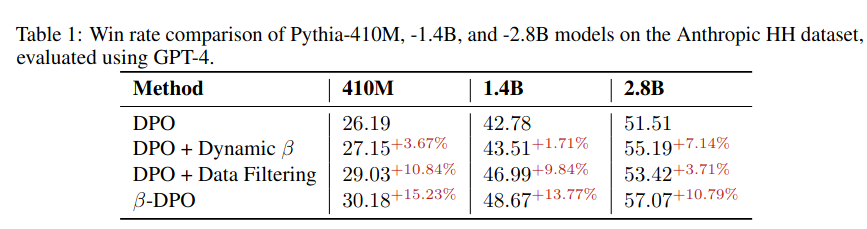
모델의 크기가 작을 수록 data filtering이 중요하고, 반대로 모델이 클수록 Dynamic \beta가 더 중요함.
이는 큰 모델이 작은 모델보다 상대적으로 optimal policy를 학습할 능력이 되기 때문.
반대로 작은 모델은 filtering을 통해서 안좋은 데이터를 걸려줘야함.
6.2. Necessity of Batch-Level Dynamic β Calibration
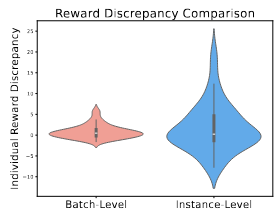
위 그림을 보면, instance-level이 batch-level보다 이상치를 확대 해석하는 것을 볼 수 있음.
이러한 해석은 \beta 값의 변동이 크다는 것을 보여주며, 결론적으로 안정적인 학습이 불가능하다는 것을 시사함.
'RLHF' 카테고리의 다른 글
| [RLHF] Direct Preference-based Policy Optimization without Reward Modeling 0 | 2024.07.04 |
|---|---|
| [RLHF] Direct Preference Optimization:Your Language Model is Secretly a Reward Model 0 | 2024.07.01 |